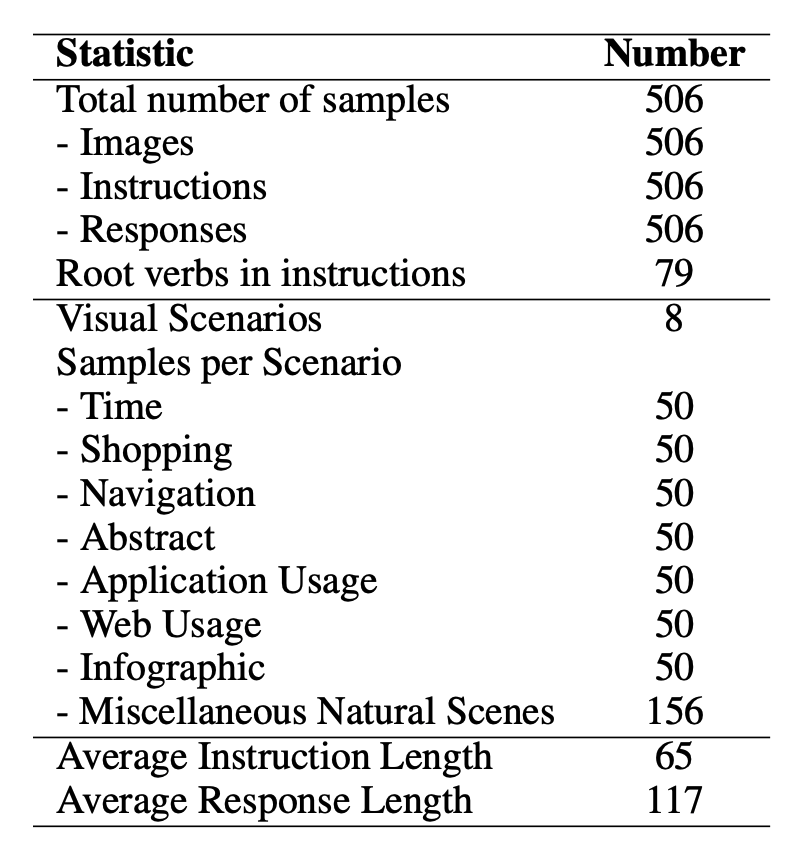
Accuracy scores on the Test dataset (506) examples of ConTextual
| # | Model | Method | Source | Date | ALL | Time | Shop. | Nav. | Abs. | App. | Web. | Info. | Misc. NS. |
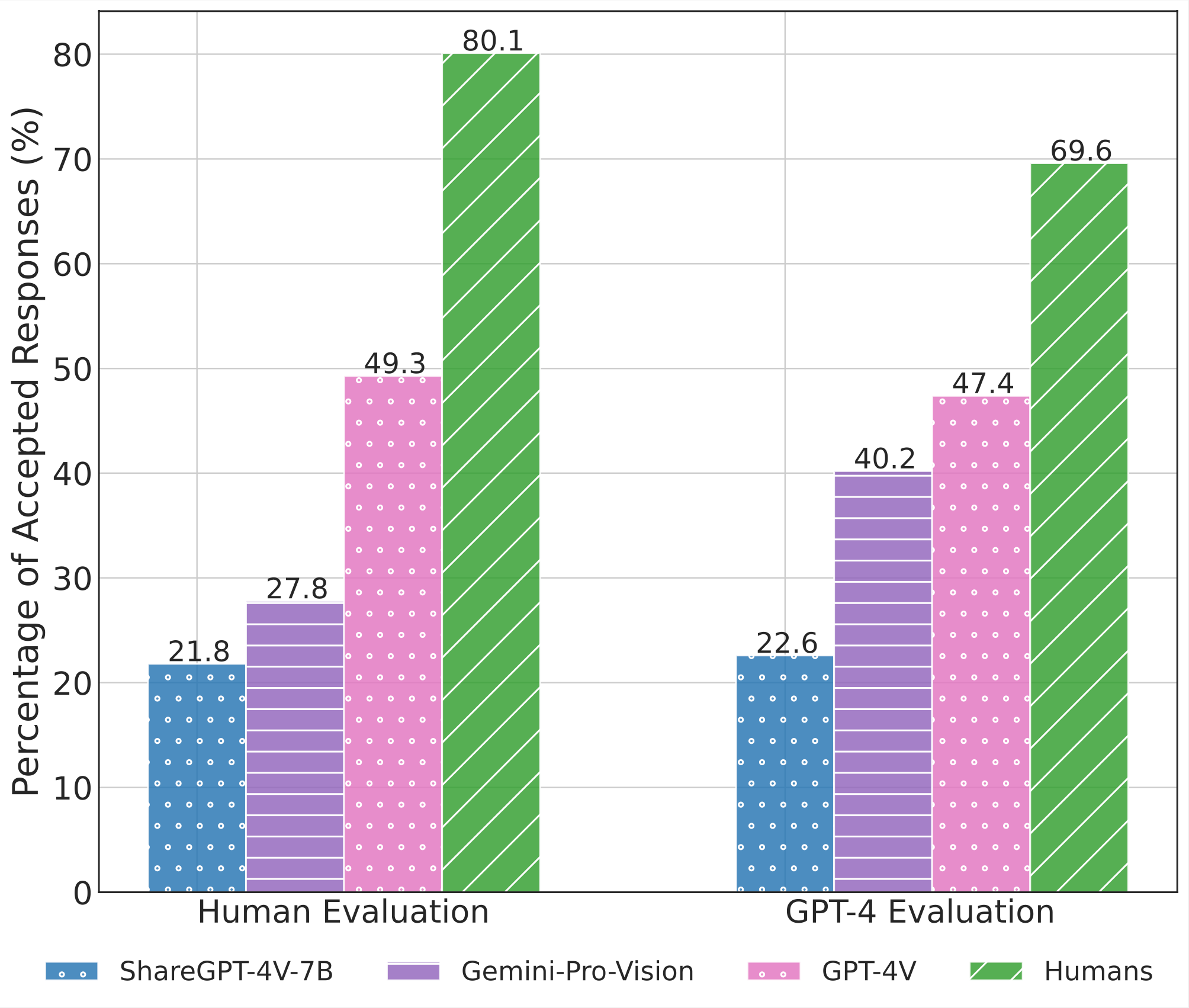
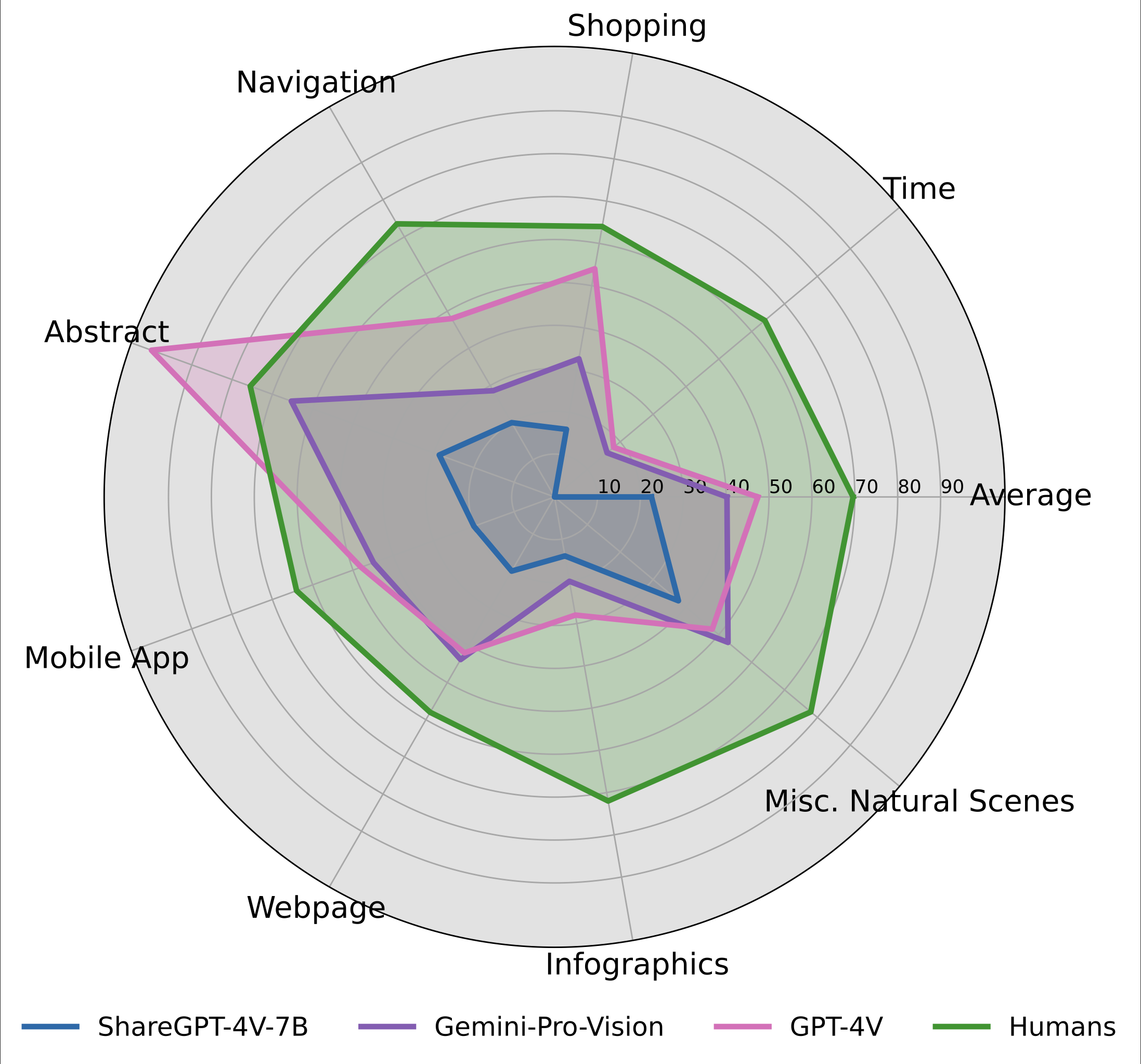
| - | Human Performance | - | Link | 2024-01-24 | 69.6 | 64.0 | 64.0 | 73.5 | 75.5 | 64.0 | 58.0 | 72.0 | 78.0 |
| 1 | GPT-4o 🥇 | LMM 🖼️ | Link | 2024-05-18 | 62.8 | 32.0 | 70.0 | 60.0 | 98.0 | 72.0 | 62.0 | 48.0 | 64.7 |
| 2 | GPT-4o-mini-2024-07-18 🥈 | LMM 🖼️ | Link | 2024-07-18 | 61.7 | 22.0 | 62.0 | 62.0 | 98.0 | 72.0 | 64.0 | 42.0 | 67.3 |
| 3 | Claude-3.5-Sonnet-2024-06-20 🥉 | LMM 🖼️ | Link | 2024-07-18 | 57.5 | 22.0 | 52.0 | 66.0 | 96.0 | 68.0 | 64.0 | 44.0 | 56.7 |
| 4 | Gemini-1.5-Flash-Preview-0514 | LMM 🖼️ | Link | 2024-05-18 | 56.0 | 30.0 | 51.0 | 52.1 | 84.0 | 63.0 | 63.2 | 42.8 | 61.7 |
| 5 | Gemini-1.5-Pro-Preview-0514 | LMM 🖼️ | Link | 2024-05-18 | 52.4 | 24.0 | 46.9 | 39.6 | 84.0 | 45.8 | 59.2 | 43.8 | 64.0 |
| 6 | GPT-4V(ision) | LMM 🖼️ | Link | 2024-01-24 | 47.4 | 18.0 | 54.0 | 48.0 | 100.0 | 48.0 | 42.0 | 28.0 | 48.0 |
| 7 | Gemini-Pro-Vision | LMM 🖼️ | Link | 2024-01-24 | 40.2 | 16.0 | 32.7 | 28.6 | 65.3 | 44.9 | 43.8 | 20.0 | 52.8 |
| 8 | Claude-3-Opus-2024-02-29 | LMM 🖼️ | Link | 2024-03-05 | 38.1 | 18.0 | 32.0 | 34.0 | 68.0 | 44.0 | 38.0 | 18.0 | 44.7 |
| 9 | LLaVA-Next-34B | LMM 🖼️ | Link | 2024-03-05 | 36.8 | 10.0 | 36.0 | 30.6 | 66.0 | 36.0 | 28.0 | 12.0 | 51.3 |
| 10 | LLaVA-Next-13B | LMM 🖼️ | Link | 2024-03-05 | 30.3 | 0.0 | 28.6 | 32.0 | 60.0 | 18.0 | 32.0 | 10.0 | 40.4 |
| 11 | ShareGPT-4V-7B | LMM 🖼️ | Link | 2024-01-24 | 22.6 | 0.0 | 16.0 | 20.0 | 28.6 | 20.0 | 20.0 | 14.0 | 37.7 |
| 12 | GPT-4 w/ Layout-aware OCR + Caption | LLM 👓 | Link | 2024-01-24 | 22.2 | 6.0 | 16.0 | 24.0 | 57.1 | 14.0 | 18.0 | 8.0 | 27.3 |
| 13 | Qwen-VL | LMM 🖼️ | Link | 2024-01-24 | 21.8 | 4.0 | 20.0 | 24.0 | 53.1 | 6.0 | 18.0 | 14.0 | 27.3 |
| 14 | LLaVA-1.5B-13B | LMM 🖼️ | Link | 2024-01-24 | 20.8 | 4.0 | 10.0 | 18.0 | 44.9 | 16.0 | 26.0 | 4.0 | 29.7 |
| 15 | mPLUG-Owl-v2-7B | LMM 🖼️ | Link | 2024-01-24 | 18.6 | 4.0 | 8.0 | 24.0 | 32.7 | 20.0 | 10.0 | 12.0 | 26.0 |
| 16 | GPT-4 w/ Layout-aware OCR | LLM 👓 | Link | 2024-01-24 | 18.2 | 8.0 | 20.0 | 18.0 | 34.7 | 10.0 | 16.0 | 16.0 | 20.7 |
| 17 | GPT-4 w/ OCR* | LLM 👓 | Link | 2024-01-24 | 15.9 | 4.0 | 10.0 | 14.0 | 30.6 | 8.0 | 16.0 | 28.6 | 16.9 |
| 18 | LLaVAR-13B | LMM 🖼️ | Link | 2024-01-24 | 14.9 | 10.0 | 16.0 | 6.0 | 44.9 | 8.0 | 10.0 | 6.0 | 16.7 |
| 19 | BLIVA | LMM 🖼️ | Link | 2024-01-24 | 10.3 | 2.0 | 4.0 | 14.0 | 24.5 | 4.0 | 8.0 | 4.0 | 14.7 |
| 20 | InstructBLIP-Vicuna-7B | LMM 🖼️ | Link | 2024-01-24 | 9.7 | 2.0 | 4.0 | 16.0 | 20.0 | 6.0 | 12.0 | 2.1 | 12.0 |
| 21 | Idefics-9B | LMM 🖼️ | Link | 2024-01-24 | 7.7 | 4.0 | 2.0 | 12.0 | 12.0 | 0.0 | 6.0 | 2.0 | 13.3 |